「AI単体は強いのに、人+AIだと弱くなる」医療とAIがややこしく見える理由
医療AIの議論が混線しやすいのは、AIの性能そのものよりも 「人が介在した瞬間に、評価対象が“モデル”から“システム”に変わる」からです。
そしてシステム評価は、条件が少し違うだけで結論が反転しやすい。
以下、その“反転ポイント”を、実際の研究例を挟みながらもう少し丁寧に整理します。
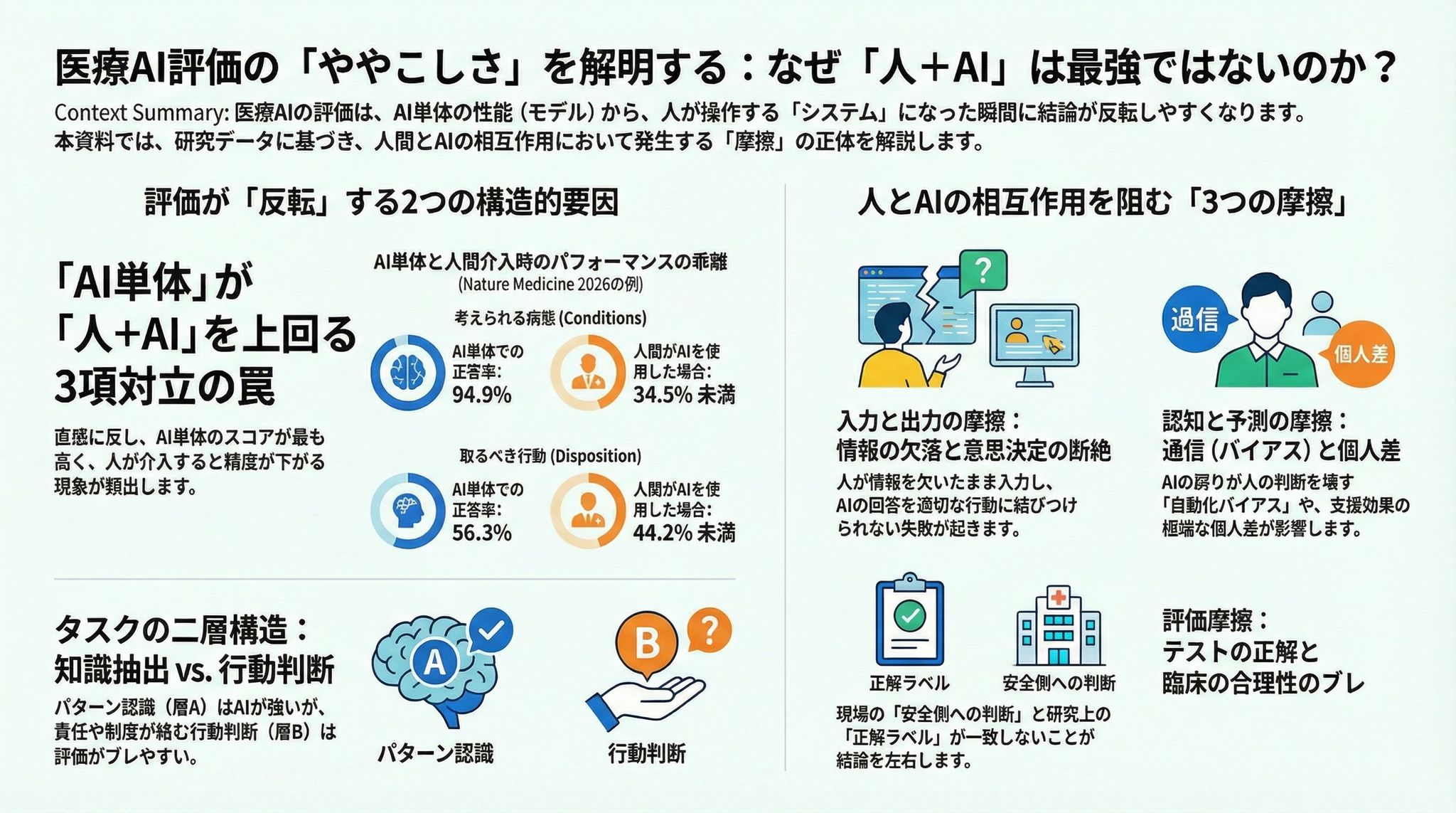
1. そもそも比較が3項対立になっている
医療AIの研究で頻出するのは、この3つの比較です。
- 人だけ(医師だけ/一般参加者だけ)
- AIだけ
- 人+AI
直感では「人+AIが最強」になりそうですが、研究ではしばしば AIだけが最高点で、人+AIは伸びない(あるいは下がる)ことがあります。
この時点で、議論の焦点は「AIが賢いか」ではなく、人がAI情報をどう取り込み、どう誤るかに移ります。
2. タスクが二層構造で、層ごとに難しさが違う
同じ“医療の問題”でも、実は別物が混ざっています。
層A:候補を挙げる(鑑別、所見抽出、可能性の列挙)
比較的「知識」や「パターン認識」の勝負になりやすい。
層B:次の行動を決める(受診判断、検査計画、運用判断)
いわゆる disposition(救急か・受診か・様子見か等)。
ここは 安全側、制度、前提条件、責任が入り込みやすく、「唯一の正解」にしにくい。
この二層が混ざると、「AIは強い/弱い」の印象が簡単にぶれます。
3. 具体例1:一般の人 × LLM(Nature Medicine 2026)が示した“ズレ”
Nature Medicine の研究は、英国の一般参加者1,298人に、10個の医療シナリオについて
- underlying conditions(考えた病態・候補)
- disposition(取るべき行動) を答えさせ、LLM支援(GPT‑4o / Llama 3 / Command R+)と対照群を比較したものです。
ここで重要なのは、結果が 「AIの能力」ではなく「やり取りの失敗」を強く示唆している点です。
- LLM“単体”で解かせると、conditionsは 94.9%、dispositionは 平均56.3%。
- しかし人が使うと、conditionsは 34.5%未満、dispositionは 44.2%未満で、しかも対照群より良くならない。
著者らは、チャット履歴の分析から
- 参加者が 情報を欠けた形で入力するケース
- LLMが 質問意図を誤解するケース
- LLMが候補を出しても、参加者が それを採用しない/行動判断に結びつけないケース などを「人−LLM相互作用の問題」として挙げています。
さらにややこしいのが、標準ベンチマーク(知識テスト)や、LLMで“人間を模擬”したシミュレーションでは、この失敗が予測できなかったという主張です。
つまり「AIは正解を言える」ことと、「人がそれを引き出して使える」ことが別だ、という話になっています。
4. 具体例2:医師 × LLM(JAMA Network Open 2024)が示した“伸びなさ”
医師側でも、似た構図が出ています。
JAMA Network Open のランダム化試験では、50人の医師(研修医・指導医)を
- 従来リソース(例:UpToDate や Google 等)のみ
- 従来リソース+LLM(GPT‑4) に割り付け、臨床推論スコアを比較しました。
結果は端的で、
- 医師+LLMの推論スコア中央値 76%
- 医師+従来リソース 74% 差は有意ではありませんでした(P=.60)。
一方で探索的分析として、
- LLM単体は従来リソース群より 16ポイント高い とも報告されています。
ここで起きているのも、「AIが答えを持てる」ことと「医師がその答えを臨床推論に統合できる」ことが一致しない、というズレです。
5. 具体例3:画像診断AIは“過信”と“過小評価”の両方で崩れる
LLMとは別系統の画像診断AIでも、「人+AI」の不安定さがはっきり出ています。
5-1) 誤ったAI提案が、人の判断を壊す(自動化バイアス)
RSNAの紹介している Radiology 論文(Dratsch ら)では、AIが示すBI‑RADSカテゴリが誤っている状況で、読影医の正答率が大きく落ちることが示されています。
たとえばプレスリリースの記載では、
- 経験の浅い読影医:AIが正しい時は正答が 約80%だが、AIが誤ると 20%未満へ低下
- 経験豊富な読影医:82% → 45.5%へ低下 という形で、経験があっても影響を受けることが示されています。
「AIが間違うと危ない」というより正確には、AIの間違いが“人の間違い方”まで変える、というややこしさです。
5-2) AI支援の効果は、人によってプラスにもマイナスにもなる(異質性)
Nature Medicine 2024(Yu ら)は、140人の放射線科医×胸部X線15タスクで「AI支援の効果が人によって大きく異なる」ことを示しました。
重要なのは次の点です。
- 経験年数やサブスペシャリティ、AIツールへの慣れといった “ありがちな説明変数”が、AI支援の効果を当てにくい。
- そして AIの誤り(AI error)の発生が、支援効果を強く左右し、半数程度の個別病変では不正確なAI予測が成績を悪化させ得る、という主張。
つまり「AIを配れば底上げ」ではなく、誰に・どんな誤り方のAIを・どんな提示で渡すかまで含めて結果が変わる。
6. それでも「人+AIが良くなる」研究は確かにある
ここまで読むと「じゃあ人+AIって基本ダメ?」となりがちですが、そう単純でもありません。
JAMA Network Open 2020(Schaffter ら、DM DREAM Challenge)では、乳房X線(マンモ)で AIアルゴリズム群と単独読影医の組み合わせが、単独読影医より全体精度が高いことが示されています。
また推定として、リコール率(精査回し)を 0.095→0.08に下げうる、という議論も書かれています(臨床での追加検証が必要、という留保つき)。
同じ“人+AI”でも、
- AIをどう統合したか
- 何を最適化しているか(感度・特異度・作業量など)
- 評価環境がどれだけ現場に近いか で結果が変わり得る、ということです。
7. 「ややこしさ」の正体を分解すると、だいたい5つの摩擦に落ちる
ここからは研究例を踏まえた“構造”の話です。
医療AIの結果が割れるとき、多くは以下のどこか(複数)で摩擦が起きています。
(1) 入力摩擦:情報がモデルに届くまでに欠ける
Nature Medicine 2026 では、参加者が情報を欠いたまま入力したり、LLMが意図を取り違えたりする例が議論されています。
AI単体評価は「ケースが全部与えられる」前提になりやすいので、ここでギャップが生まれます。
(2) 出力摩擦:AIの答えが“行動”に変換されない
AIが候補を出しても、人がそれを信頼しない/理解しない/行動判断に接続できない。
Nature Medicine 2026 は、LLMが関連候補を出しても参加者が一貫して採用しない可能性を示しています。
(3) 認知摩擦:過信と過小評価の両方がある
- 過信(自動化バイアス):誤ったAI提案に引っ張られる(Dratsch ら)。
- 過小評価:AIを軽視して取り込めない(後述の“信念更新”の話)
同じ職種でも個人差が大きく、平均すると見えにくい。
(4) 予測摩擦:AI支援の効果が“人によって符号ごと違う”
Yu らが示したのは、AI支援がプラスにもマイナスにもなり、その予測が簡単でないことです。
(5) 評価摩擦:研究の採点軸と、臨床の合理性がずれる
特に disposition(受診判断)は「安全側」「制度」「責任」などが絡み、研究の“正解”と現場の判断の一致がそもそも難しい。
だから、同じ能力でも評価設計で印象が変わります。
8. もう一段ややこしくする要因:人は“ベイズ更新”をうまくやらない
「人+AIが伸びない」を、もう少し定量的に説明しようとする研究もあります。
ベイズ更新とは、新しい情報やデータを得るたびに、ある事象が起こる確率(信憑性)をリアルタイムで修正していく統計学的な手法のことです。
簡単に言うと、「経験やデータをもとに、自分の持っている『予測』をどんどんアップデートしていく仕組み」です。
NBERのワーキングペーパー(Agarwal ら)は、放射線科医を使った情報実験で
- AI予測の提示が 必ずしも成績を上げない
- その背景として、放射線科医が AI予測を過小評価し(underweight)、さらに 自分の情報とAI情報を統計的に独立みたいに扱ってしまう(依存を無視する) といった「信念更新の誤り」を論じています。
この枠組みのポイントは、「AIが正しい」だけでは足りず、人が“正しい重み付け”で統合できないと、追加情報があっても性能が上がらない(場合によっては下がる)という説明が可能になるところです。
9. 「AIモデルが古い」問題は、実は“再現性”の話に直結する
モデル名が変わったり提供形態が変わったりすると、「その論文、いま意味あるの?」となりがちです。
ただ、今回の論点は 特定モデルの固有性能というより、
- AI単体での高得点
- 人が介入したときの劣化
- ベンチマークやシミュレーションが、その劣化を予測できない
という“相互作用の失敗”にあります。Nature Medicine 2026 はまさにそこを主張しています。
モデルが入れ替わっても、このタイプの失敗モードが消える保証はない、という意味で「読む価値が残る」類の論文です。
ややこしさは「矛盾」ではなく「条件依存」
ここまでの話を一行にすると、
医療AIは、人・タスク・提示・評価が少し変わるだけで、人+AIの効果がプラスにもマイナスにも転ぶ。だから結論が割れて見える。
そして研究の分岐点は、だいたい次の問いに集約されます。
- 何をさせた?(鑑別/行動判断)
- 誰が使った?(一般/医師/放射線科医)
- AIはどう提示された?(順位だけ/確率/根拠/同時提示の量)
- AIはどんな間違い方をした?(誤りの頻度と方向)
- 成績は何で測った?(正解ラベル/安全側評価/作業量)
「医師が介在したほうがよい」に混ざる2つの意味
1) ガバナンス(責任・安全)としての介在
- 最終判断・説明責任・責任の所在を、人間(医師)に置く
- 患者の状況や制度・倫理を踏まえた判断を担保する
これは「医師が介在=安全設計の一部」という話で、社会実装としては重要です。ただ、ここで言っている“よい”は 性能(正答率)が上がることとは別です。
2) パフォーマンス(精度・質)としての介在
- 医師が入れば、AI単体よりも(あるいは医師単体よりも)診断や判断の質が上がる
こちらは“期待”として語られがちですが、研究結果を見る限り 自動的には成立しません。
この2つが混同されると、医療者側は「責任の観点」で正しい話をしているのに、受け手(研究を読んでいる側)は「精度の観点」で反証を持ち出して、議論がすれ違います。
研究が突きつけているのは「介在=精度向上」ではない、という点
医師がLLMを使っても、推論スコアが有意に上がらない例
JAMA Network Open のランダム化試験では、医師50人が「従来リソースのみ」vs「従来リソース+LLM」で比較され、診断推論スコア中央値は 76% vs 74%で有意差なし(P=.60)でした。さらに探索的分析で LLM単体は従来リソース群より16ポイント高いとも報告されています。
ここで観測されているのは、「医師が使えば必ず伸びる」ではなく “アクセスを渡すだけでは伸びない”という現象です。
一般の人でも「AI単体は強いのに、人が使うと伸びない」例
Nature Medicine(Beanら)の一般参加者実験でも同型のズレが出ています。シナリオを直接モデルに解かせると「関連する病態を少なくとも1つ挙げられる」割合は高く、disposition(受診行動)の正答も一定程度あります(例:GPT‑4oで病態94.7%、disposition 64.7%)。
一方で、人がLLMを使った条件では、参加者は対照群より「関連病態を当てにくい」など、“モデル単体の能力”がそのまま“利用成果”に変換されないことが示されています。
この2本立て(医師でも一般でも起きる)は、「医師が介在すれば精度が上がるはず」という主張に対して、真正面から“条件付き”を要求します。
「医師が入れば上がるはず」がズレる理由(よく起きる3つの落とし穴)
落とし穴A:介在が“検出器”として機能する前提が置かれている
「医師が最後に見れば誤りを弾ける」という前提は、実は強い仮定です。
放射線領域の例ですが、RSNAが紹介した研究では、AIが誤ったBI‑RADSカテゴリを提示すると、経験の浅い読影医は正答が「ほぼ80% → 20%未満」に、経験豊富な読影医でも「82% → 45.5%」へ落ちた、とされています。
つまり “医師がいる=誤りを必ず見抜ける”ではなく、誤った助言が入ることで 医師の判断そのものが崩れる状況があり得る、ということです。
落とし穴B:「人+AI」を平均で語りすぎる
AI支援の効果は一様ではなく、人やタスクで符号(プラス/マイナス)が割れることがあります。Nature Medicine(Yuら)の大規模研究は、140人の放射線科医×胸部X線15タスクで、AI支援効果が不均一(heterogeneous)である点を扱っています。
この種の不均一性があると、「医師が介在した方がよい」という平均論は、現場感としては言いやすい一方で、研究の読みとしては “誰にとって・どのタスクで・どんな誤り方のAIで”が抜け落ちやすい。
落とし穴C:「統合(情報の重み付け)が難しい」を軽視している
NBERのワーキングペーパー(Agarwalら)は、放射線科医がAI予測を提示されても平均的に性能が上がらない背景として、信念更新の誤り(AI予測を過小評価する、自己情報とAI情報を独立とみなす等)を論じています。
ここが効くと、「医師が介在」しても、介在が“賢い統合”に直結しないことが説明できます。
では「医師が介在したほうがよい」という主張は、どこで意味を持つのか
ここは否定/肯定の二択ではなく、主張の射程の話になります。
- 精度が上がるという意味では:研究上、条件次第で成立しない(むしろ逆転もあり得る)。
- 責任と安全の構造という意味では:医師介在は別軸で重要(ただしそれは“精度保証”とは別の設計要件)。
医療者側の言説はしばしば後者(責任・安全・社会実装)を言っているのに、聞き手は前者(精度・有効性)として受け取ってしまう——ここが「ポイントがずれて見える」主因だと思います。
ひとことで整理すると
「医師が介在すればよい」は、責任の話としては筋が通る。
しかし、研究が問題にしているのは “介在そのもの”ではなく、人とAIが噛み合わないと成果が出ないという点で、そこに答えていないとズレます。
混乱しやすいのはまさにこの「責任の議論」と「性能の議論」の混線なのです。
医療AIは安易に結論を出せない
医療AIまわりは、同じ「性能」や「有効性」という言葉でも、実際には見ている対象がズレやすいです。たとえば、次のどれを言っているのかで結論が変わります。
- AI単体の能力(理想的な入力がそろった“試験”での正解率)
- 人がAIを使ったときの結果(入力の欠け、解釈、確認行動、時間制約まで含んだ“運用”)
- 現場のアウトカム(診断精度だけでなく、見落とし・過剰受診・作業量・責任分担なども絡む)
さらに、タスクが「鑑別を挙げる」なのか「受診や検査の判断(disposition)」なのかでも難しさが変わるので、研究ごとに“何を証明したのか”が別物になりがちです。